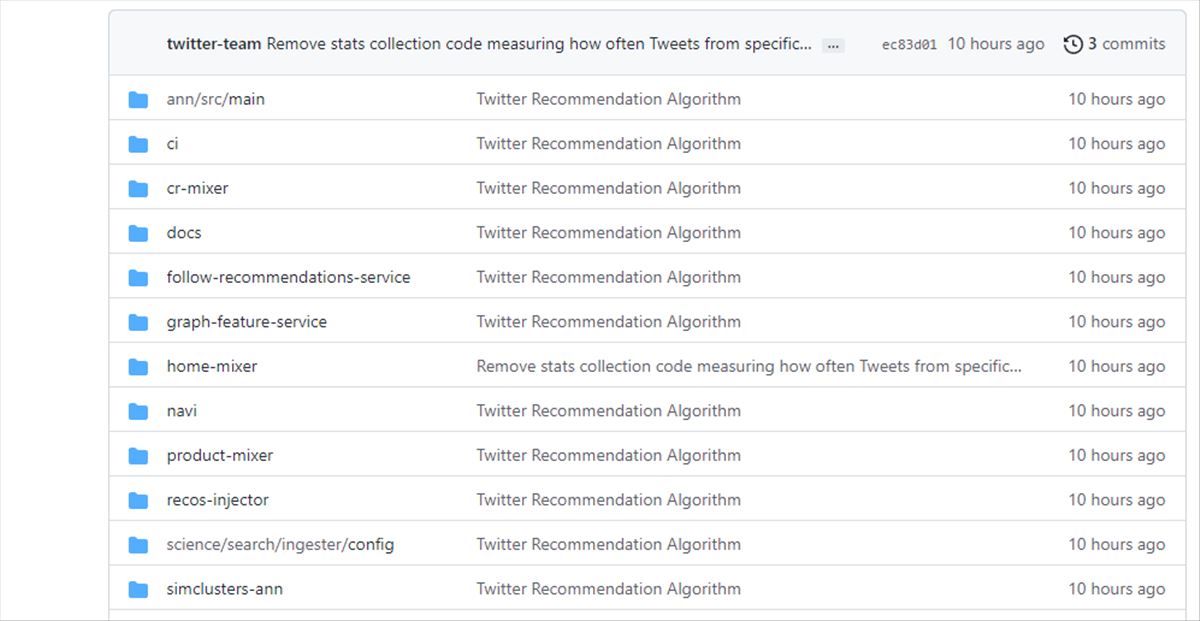
Twitter
ha publicado el código fuente de su algoritmo de recomendación en
GitHub, como respuesta a la propuesta de Elon Musk de hacerlo público
hace casi un año. En una conversación en Twitter Space, Musk afirmó que
esperaba que los usuarios pudieran encontrar posibles «problemas» en el
código y ayudar a mejorarlo.
Una oportunidad para la transparencia y la colaboración
La
decisión de Twitter de hacer público el código de su algoritmo de
recomendación es una oportunidad para la transparencia y la colaboración
en la mejora de la tecnología. La publicación del código es una muestra
de que la compañía está abierta a la retroalimentación y dispuesta a
mejorar su algoritmo.
El algoritmo de recomendación de Twitter se
encarga de mostrar los tweets en la sección «Para ti» de la plataforma.
El código publicado cubre únicamente esta sección, por lo que no se ha
liberado el código subyacente del algoritmo de búsqueda o cómo se
muestra el contenido en otras partes de Twitter.
Los detalles encontrados en el código
Los
usuarios de Twitter han encontrado detalles interesantes en el código
del algoritmo de recomendación. Por ejemplo, Jane Manchun Wong señaló
que «el algoritmo de Twitter etiqueta específicamente si el autor del
tweet es Elon Musk». Esto podría explicar por qué los tweets de Musk
aparecen con tanta frecuencia. Wong también señaló que el algoritmo
tiene etiquetas que indican si el autor del tweet es un «usuario
poderoso» y si es republicano o demócrata.
La respuesta de Elon Musk y de Twitter
Cuando
se le preguntó sobre este aspecto del algoritmo, Musk expresó su
desacuerdo y afirmó que «definitivamente no debería estar dividiendo a
las personas en republicanos y demócratas, eso no tiene sentido». Un
ingeniero de Twitter aclaró que las categorías solo se utilizan «con
fines de seguimiento estadístico y no tienen nada que ver con el
algoritmo». Dijo que las etiquetas están destinadas «a asegurarnos de no
tener sesgos hacia un grupo en particular». Sin embargo, no se explicó
por qué Musk tenía su propia categoría.
La publicación del código
de su algoritmo de recomendación por parte de Twitter es una buena
noticia para la transparencia en la industria tecnológica. Permitir que
los usuarios accedan al código fuente del algoritmo es una señal de que
la compañía está abierta a recibir retroalimentación y colaboración en
la mejora de la tecnología.
Los componentes del algoritmo de recomendación de Twitter
El
algoritmo de recomendación de Twitter está compuesto por varios
servicios y trabajos que se interconectan. Aunque hay muchas áreas de la
aplicación en las que se recomiendan Tweets, en este artículo nos
centraremos en el feed «Para ti» del timeline.
El algoritmo de recomendación de Twitter consta de tres etapas principales:
- Obtener los mejores Tweets de diferentes fuentes de recomendación mediante un proceso llamado «sourcing de candidatos».
- Clasificar cada Tweet utilizando un modelo de aprendizaje automático.
- Aplicar
heurísticas y filtros, como filtrar Tweets de usuarios que has
bloqueado, contenido para adultos y Tweets que ya has visto.
El
servicio que se encarga de construir y servir el feed «Para ti» es Home
Mixer. Home Mixer está construido sobre Product Mixer, un marco de
trabajo personalizado de Scala que facilita la creación de feeds de
contenido. Este servicio actúa como columna vertebral de software que
conecta diferentes fuentes de candidatos, funciones de puntuación,
heurísticas y filtros.
Cómo se eligen los Tweets
La base
de las recomendaciones de Twitter es un conjunto de modelos y
características principales que extraen información latente de los datos
de Tweets, usuarios y compromisos. Estos modelos buscan responder
preguntas importantes sobre la red de Twitter, como «¿Cuál es la
probabilidad de que interactúes con otro usuario en el futuro?» o
«¿Cuáles son las comunidades en Twitter y cuáles son los Tweets más
populares dentro de ellas?».
La tubería de recomendación de
Twitter está compuesta por varios componentes que consumen estas
características. El proceso comienza con la obtención de los candidatos
de diferentes fuentes de recomendación.
Fuentes de candidatos
Twitter
tiene varias fuentes de candidatos que utiliza para recuperar Tweets
recientes y relevantes para el usuario. Para cada solicitud, se intentan
extraer los mejores 1500 Tweets de una piscina de cientos de millones
de Tweets a través de estas fuentes. Los candidatos se encuentran entre
las personas a las que sigues (En red) y las que no (Fuera de red). En
el feed «Para ti», los Tweets dentro de la red y fuera de la red tienen
un 50% de probabilidad en promedio, aunque esto puede variar de un
usuario a otro.
Fuentes dentro de la red
La fuente dentro
de la red es la fuente de candidatos más grande y tiene como objetivo
proporcionar los Tweets más relevantes y recientes de los usuarios que
sigues. Los Tweets de los usuarios que sigues se clasifican
eficientemente en función de su relevancia utilizando un modelo de
regresión logística. Los mejores Tweets se envían a la siguiente etapa.
Una
vez que se han obtenido los candidatos a aparecer en el timeline, se
procede a ranquearlos para decidir su orden de aparición. El objetivo es
ofrecer los tweets más relevantes y con mayor potencial de interacción
para el usuario. Para ello, se utiliza una red neuronal con
aproximadamente 48 millones de parámetros, que se entrena continuamente
con las interacciones de los usuarios con los tweets.
La red
neuronal utiliza miles de características para determinar la relevancia
de cada tweet y otorgarle una puntuación. De estas puntuaciones, se
seleccionan las 10 más altas para darle una clasificación final al
tweet. Es importante destacar que en este punto del proceso, todos los
tweets se tratan por igual, sin importar su origen.
Heurísticas, filtros y características del producto
Después
del proceso de ranqueo, se aplican una serie de heurísticas, filtros y
características del producto para crear un timeline equilibrado y
diverso. Algunos ejemplos de estas características incluyen:
- Filtros
de visibilidad: se eliminan tweets basados en su contenido y las
preferencias del usuario. Por ejemplo, se eliminan tweets de cuentas
bloqueadas o silenciadas.
- Diversidad de autores: se evita que aparezcan muchos tweets seguidos del mismo autor.
- Balance de contenido: se asegura de que se entregue una cantidad equilibrada de tweets de In-Network y Out-of-Network.
- Fatiga
basada en feedback: se disminuye la puntuación de ciertos tweets si el
usuario ha proporcionado comentarios negativos sobre ellos.
- Prueba
social: se excluyen tweets Out-of-Network que no tengan una conexión de
segundo grado con el tweet, como una medida de calidad. En otras
palabras, se asegura de que alguien que el usuario sigue ha interactuado
con el tweet o sigue al autor del tweet.
- Conversaciones: se proporciona más contexto para las respuestas al enlazarlas con el tweet original.
- Tweets
editados: se determina si los tweets en el dispositivo están
desactualizados y se envían instrucciones para reemplazarlos con las
versiones editadas.
Mezcla y entrega
Finalmente, el
servicio Home Mixer tiene una selección de tweets listos para enviar al
dispositivo del usuario. Como último paso, se mezclan los tweets con
otro contenido no relacionado con tweets, como anuncios, recomendaciones
de seguimiento y sugerencias para nuevos usuarios, y se devuelve al
dispositivo para mostrarlos.
Serán muchos los detalles que aparecerán a partir de ahora, sin duda.
pueder bajar el código en este enlace.
Más información en blog.twitter.com.